Projects:2015s1-04 Detecting Cyber Malicious Command-Control (C2) Network Traffic Communications
Contents
- 1 Members
- 2 Supervisors
- 3 Introduction
- 4 Related Work
- 5 Deliverables
- 6 Technical Challenges
- 7 Proposed Method
- 8 Management Plan
- 9 Citations and References
- 10 Appendix
Members
Lu Yao
Wang Jing
Pham Thanh Thien
Raoux Jonathan
Supervisors
Cheng Chew Lim
Hong Gunn Chew
Adriel Cheng
Introduction
Purpose
This document is to served multiple purposes. Firstly this document is used to define the goals and objectives of the project to the stakeholders. Secondly this document will define the method proposed by the project team to complete the project. Thirdly this document will also define the previous work done by other researchers on topics related to this project. Finally this document will define the budget, risks and timelines for the proposed method. The stakeholders for this project are the Defence Science and Technology Organisation(DSTG), the University of Adelaide(UoA), the supervisors for this project and the team members for this project. The supervisors for this project are Cheng Chew Lim(Head of School, School of Electrical & Electronic Engineering at the UoA), Hong Gunn Chew(Teaching Laboratories Manager at the UoA), Adriel Cheng(Research fellow at the DSTG). The team members for this project are Lu Yao(UoA), Pham Thanh Thien(UoA), Wang Jing(UoA) and Raoux Jonathan (UoA). This document is based on the Project Proposal Draft[15] and the feedback provided by Robert Moric.
Definitions, Acronyms, and Abbreviation
C2 – Command and Control
DDOS – Distributed Denial of Service
DSTG – Defence Science and Technology Group
Flow – Sequence of related packets that share at a minimum IP transport protocol, source/destination IP address and source/destination port (if IP transport protocol is UDP or TCP)
IRC – Internet Relay Chat
ML – Machine Learning
P2P – Peer-to-Peer
The Group – Yao Lu, Thanh Thien Pham, Jonathan Raoux, Jing Wang
The Project – Hornours Project 4, Detecting Cyber Malicious Command – Control (C2) Network Traffic Communications
Weka – Waikato Environment for Knowledge Analysis
Background & Significance
Motivation
This project is very important to the security of the internet as a whole. This is due to the increase in the number of botnets and their respective sizes [1]. This increase in the number of infected devices is due to the number of new devices which can access the internet and the lack of security on those devices [2][3]. This lack of security is mainly due to a lack of information being provided to the owners of these devices but is not the only source [2].
Botnets are interconnected network of bots (or infected devices) which are being controlled by a botmaster without the owner of these devices knowledge. The bots can be devices of any type as long as they are able to be connected to the botmaster using a network. The most used network is the Internet due to its availability, stability and lack of security.
Botnets can cause a range of malevolent action on the internet. The first action is for the infected devices to be used by the bot master to steal any information available. Another action that can be perpetrated by a infected machine is to send spam emails to other devices. Botnets can also be used to fake internet traffic. This can be done to increase the income provided by a website through the advertising on the website but also to increase the awareness of the public to the website. Finally botnets can also be used to implement a distributed denial-of-service(DDOS) attack. A DDOS attack is an attack by many devices to remove a device or other network resource from service temporarily or permanently. DDOS attack can have very strong repercussions due to interconnectivity of the internet.
This project aims at creating a method to detect botnets before they can be used by the bot master to any malevolent action. Other method already exist but some are found to be unable to be used on the full real time traffic [4][5]. The objectives of this project are described in section 2.3 of this document.
Technical Background
Bornet
A botnet is a network of computers that a cyber criminal has infected with malicious software. This allows criminals to control those computers remotely, like an army of zombies. They could be uses to commit crime like financial fraud, identity theft, sending spams etc. With a single botnet, cyber criminals can commit billions of illegal activities in a single day. Meanwhile, the owners of these computers don’t even know they are infected.
Botnet Protocols
To avoid detection, botmasters employed several protocols with decentralized topologies and fluxing techniques. In this regard, they evolved their communication methodology from utilizing Internet Relay Chat (IRC) to taking advantage of more ubiquitous protocols and decentralized topologies such as Hypertext Transfer Protocol (HTTP) and Peer-to-Peer (P2P). In this project, the group will only focus on the HTTP methodology.
Botnet Lifecycle
Leonard et al. divided the botnet lifecycle into four phases, which are:
• Formation Phase
The botmaster spreads bots through Internet to make other machines become member of the botnet.
• Command and Control (C2) Phase
The bots (infected machines) that are enslaved will receive instructions from the bot master on a regular basis during C&C phase.
• Attack Phase
During this phase, the infected machines, which are the bots, will regularly receive instructions from botmaster and carry malicious activities accordingly.
• Post-Attack Phase
After attach phase some bots might be detected and removed, while the botmasters will try to probe the botnet to get information about active bots and plan for new formation.
This project will focus on the connection between bots and botmasters by analysis the netflow data transferred between them, which is in C&C phase.
Objectives
The overall goal of the project is to provide an optimal method to detect botnets using only the information provided by the NetFlow data. This method must use machine learning to classify network flows as either botnet or normal data flow. To accomplish this the goal has been separated into three objectives: determine useful fields of the NetFlow data for botnets detection, determine the optimal machine learning algorithm for botnets detection and create a real time botnet detection system.
The first objectives is to determine which field of the NetFlow data is a feature which will enable an optimal classification of the data flows in between botnet and normal traffic. This objective arises from the need to make the system work in real time but still remain able to detect a sufficiently high percentage of botnets on the network tested.
The second objective is to determine the optimal machine learning algorithm for the correct classification of network flows. This objective is due to the requirement of the project that the system use machine learning to classify the network flows. As such the machine learning algorithms need to be tested to find the optimal algorithm for this project.
The final project objective is a time dependent objective. The objective entails taking the information gathered during the first two objectives and making an optimal system which will classify the network flows in real time. This objective is due to the requirement that the system produces by this project needs to function on any network with a range of bandwidth and data speed.
Related Work
Previous Study
This project is to continue the work started by last year project group. According to the final report [9] written by the previous group, they divided their goal into three phases. The first phase involved collecting traffic data for developing or prototyping machine learning techniques. The second stage was to perform an in-depth analysis of the data by applying Machine Learning techniques on NetFlow/IPFIX datasets and evaluate the most useful fields. Both last year project team and this year project team are concentrating on the supervised learning algorithms. During the previous project, tree-based classifiers and Support Vector Machine techniques were mostly considered. This years project will consider only random forest due to DSTG requirement based on the findings of the last years project group. The third phase was to develop an Intrusion Detection System (IDS) by applying Machine Learning techniques to identify cyber-malicious traffic and devices (e.g. Botnet Command and Control, polymorphic blending attacks). This phase was not covered by last year’s project and is the focus in this project.
Literature Review
During the process of searching background literature, a free on-line machine learning course offered by Andrew Ng, Stanford University [11] was found. By completing the course, the group gained valuable knowledge relating to Machine Learning and Data Mining. To be more specific, the group members gained basic knowledge relating to several types of machine learning algorithms, understanding how to evaluate the result of classification (over-fitting/under-fitting) as well as how to adjust data and algorithms according to different situations. In addition, the book written by Witten and Frank [10] also contains some useful information relating to machine learning which is relevant to this project.
In this project, analysis of Machine Learning techniques will be conducted using Weka (Waikato Environment for Knowledge Analysis)[12]. Weka is a collection of machine learning algorithms and software developed by the University of Waikato, New Zealand. Weka was chosen because it allows the group to very easily and without waiting for an algorithm to be implemented start using the random forest machine learning algorithm. Another reason is, by taking the free on-line course offered by Waikato[13],the Weka software becomes simple to use.
After further research, several papers were consulted that investigated cyber-malicious classification using machine-learning techniques. Leyla Bilge et al.[4] considers performing random forest classifier to identify botnet C&C channels from NetFlow records. This paper describes a system called disclosure. This system is able to detect botnets without any limitations on protocol by means of NetFlow data only. Besides, a group of features (e.g. Flow size class, client access pattern class and temporal class) are identified to allow Disclosure to reliably distinguish Command-control channels from benign traffic using NetFlow records. Moreover, if the data is sampled on larger networks, the system could run in real time. The proposed system could detect botnet even if the botnets used a random temporal behaviour, if the system was trained with data that contains such botnets. The paper identified multiple false positive reduction techniques based on comparing IP to lists of known benign and malicious servers. For this project, the feature classes defined by this paper will be used. Additionally the false positive techniques will be considered when implementing the near real time system.
Fariba Haddadi et al.[5] conducted a study of using two different tree-based classifiers, which are C4.5 and Naive Bayes to identify HTTP-based botnet activity in C&C network. The proposed classifying system was focused on two botnets (Citadel and Zeus) and limited all detection to http based botnets. This limitation increased the detection rate significantly and decreased the size of the data to be looked at. During the process of classification, many features are selected, most of them are either temporal, identity, or flow size information. This project will look at testing the features identified in this paper, though some of those will not be used due to being unavailable in the netflow data provided by the DSTO.
The paper titled BotFinder [14] describes a system which is used to detect botnets similarly to the Disclosure system [4]. The differences being that the BotFinder system is based on aggregated data. This aggregated is constructed by combining all flows with the same IP and port pairs and creating a timeline of all the flows. The system focuses on using average values for the machine learning algorithm. The selected features were the average start time in between subsequent connections, the average duration of the connections, the average number of source and destination bytes per flow and the Fast Fourier Transform (FFT) of the aggregated data to detect underlying communication regularities. For this project, a modification of the FFT technique presented in this paper will be used to provide information about the periodicity of the connection in between the bots and their bot master.
Deliverables
Documentation
• Agenda for weekly meeting • Minutes for weekly meeting • Proposal seminar • Preliminary research report • Research project proposal & progress report • Final seminar • Project exhibition • Honours thesis • Final seminar for DSTG
Software
A Cyber malicious network traffic detection prototype tool which can operate on different networks and collections of traffic data.
Data
• Netflow dataset • Analysis of netflow data • Test result on Weka
Technical Challenges
The majority technical challenge that impacts the project most is the need to maintain the privacy of the users of a network. The full data being transmitted on the network contains information, which the users may not want monitored. For those reasons this project is constrained to using metadata only.
Proposed Method
This project focuses on extracting and selecting the most useful features of the NetFlow data provided to accurately detect botnets command and control communications. This project will use a random forest machine learning algorithm for all its analysis and will not look at other possible algorithms and their effects on the results. The ultimate goal of the project is to build a complete botnet detection system which will be able to handle large traffic volume and function in near real time to reliably monitor a network for botnets. This project has been divided in three stages:
1) Building a tree-based Machine Learning classifier
2) Feature extraction and selection
3) Testing and implementation on Weka
4) Netflow data capture from real network traffic
These stages will assemble into a near real time botnet detection system.
Building a tree-based Machine Learning classifier
Based on the findings of the previous year’s project team [9] and the requirement of the DSTO, it was decided to use a random forest machine learning algorithm as it provided with some of the best classifier accuracy while being simpler to understand and use. During the feature extraction and selection stage the machine learning algorithm will be implemented using WEKA. WEKA is an open source platform specialised in Machine Learning experiment and research because of its extremely diverse pre-implemented machine learning algorithms as well as the useful tools for data processing and visualisation [6]. This was decided since WEKA is simple to use and the random forest classifier has already been implemented in it.
Predicting Performance Interpretation via Probabilities
The confusion matrix can be seen as:
| Predicted Classes | |||
| Yes | No | ||
| Actual Classes | Yes | True Positive(TP) | False Positive |
| No | False Positive(FP) | True Negative(TN) | |
True Positive Rate or sensitivity:
TP/(TP + FN)
Positive predictive value or Precision:
TP/(TP + FP)
Recall is equal to True Positive Rate.
Increase Precision of the Classifier
In order to increase the precision rather than the recall value as well as get more correct prediction while reducing the false positive prediction and thus detect more botnets, some techniques were investigated to reduce the false positive rate. One of them is creating a benign list of IP addresses according to well-known Alexa-ranking websites as introduced by Bilge et al. [4]. Consequentially, flows which have IPs matching with those in the benign lists, would be rated as benign flows. The benign IP list will be growing over time. Newly infected IPs can be removed from the list if necessary. However, the chance for one trusted IP getting compromised is very low and professionals who are responsible for those IPs would take swift actions. A issue with this technique is that the data set provided by the Defence Science and Technology Organisation (DSTO) will have its IP addresses anonymised. Though this technique can be used in the final stage of the project when implementing the near real time system.
The knowledge gap is introduced as the efforts in increasing the precision value of the classifier. The simplest way is to reduce as much as possible the popular benign IPs of famous companies from suspect IP lists as described above.
Feature Extraction/Selection
Select useful features
The first part of the second stage is to go through botnet features used in research paper and select from those features to get rid of features that are not applicable in this project. This step is allocated to Jing and Jonathan.
Data Analysis
The next step is to apply data analysis on the off-line dataset given by the supervisor. The first reason of doing data analysis is to prove that those selected features are useful. Another reason is to determine which field of the NetFlow data is a feature that could be used to classify botnet from normal Netflow data. This will enable an optimal classification of the data flows in between botnet and normal traffic.
The data analysis process is decided to be taken on the Matlab, because the group members are familiar with coding on Matlab, there is no need to spend time on learning to use another tool. Moreover, Matlab has large quantities of installed function, which could be used directly so that speed up the execution procedure.
This step is divided in two parts, which allocated to Yao, Jonathan & Jing respectively. Yao will concentrate on analysis on NetFlow dataset with selected features (flow size class, temporal class, client access patterns class…etc.). Jonathan and Jing will focus on one particular feature/technique, Fast Fourier Transformation (FFT).
Deanonymisation
Netflow records contain many fields but not all of them are useful. Moreover, the correlation between flows can be discovered by investigating those useful features. Most of the public Netflow datasets contain anonymised IP addresses, therefore, we need a step to deanonymise the Netflow datasets. The correlation between flows are then evaluated by using temporal analysis.
To get information from the anonymised ip pairs, we can only know which IP is internal or external in regards to their position in the network. The deanonymisation algorithm has been designed to classify internal IPs from external IPs.
Introduction and Motivation
The deanonymisation idea is inherited from last year project when students needed to draw out the topology of network based on anonymised IPs. The basic assumption is that there are three types of IPs participating in Netflow flows:
- Internal IPs: IPs are LAN hosts located inside the infrastructure network
- External IPs: IPs of end systems on the Internet
- Infrastructure IPs: IPs of Web proxies and routers located inside the infrastructure network
The scenarios of flow instance can illustrated as follows:

- Internal IPs <-> External IPs
- Internal IPs <-> Web proxies
- Internal IPs <-> Border routers
- External IPs <-> Web proxies
- External IPs <-> Border routers
- Border routers <-> Web proxies
- Border routers <-> other Border routers
The ground truth for IP location is that internal IPs, Web proxy IPs, border router IPs are inside the infrastructure network whereas external IPs are outside the infrastructure network. The deanonymisation process is indeed expected to classify internal-located IPs from external IPs based on the assumption above. Once the topology is known, it opens up various ways to extract information from Netflow data.
Defninition
Internal IP: it belongs to intranet
External IP: it belongs to the Internet
Conflict IP / Instrastructure IP: connects to both internal IP and external IP (border routers, web proxies, AARNET servers, etc.)
Cluster: entity containing two separate regions in which IPs are classified into
Bridge: the IP address appears in two or more clusters
Colours: C = {C0,C1,C2,C3,...,Cn} each colour Ci has two schemes: dark or bright
Note: odd number equals dark scheme and even numbers equals bright scheme analogously. Each IP would be assigned a scheme of dark or bright by the algorithm.
Algorithm
The basic steps:
- Colourise IP numbers with colours given
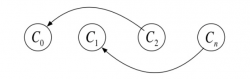
- Link these colours with each other by making graph similar to
- Based on the colour graph, identify smallest set of colours that can colourised on data. On the above graph, the primitive colour is {C0,C1}.
- Based on colour code and colour graph with regard to primitive colours, the algorithm generates an equivalent colour code (in primitive colours) for each IP number. For example, colour code is even then the IP should be in left column, whereas colour code is odd then the IP should be in right column (there are two columns of numbers to put IPs in).

Algorithm
Input: IP_pairs_list.txt
Output: the deanonymised IP list. Column 1: internal IPs, column 2: external IPs
Loop through rows of Data row by row and colourise IP numbers in them
first = current_row[0];
second = current_row[1];
Case1: both first and second are not colourised yet
- Pick the next colour Ci (supposed the previous is Ci-1)
- Colourise first with bright theme Ci[0]
- Colourise second with dark theme Ci[1]
- Continue the loop
Case 2: first is not coloured yet but second is already coloured
- Use the colour of second to colourise first but with the opposite theme
- If colour code of second is x then colour code for first is (x - x%2) + (1 - x%2)
- Continue the loop
Case 3: second is not coloured yet but first is already coloured
- Similar to case 2
Case 4: both second (belongs to cluster Ck) and first (belongs to cluster Cl) have been colourised already
- Identify relationship between these 2 colours (Ck and Cl)
Statistical Features
Introduction
Apart from the original features of the Netflow dataset, the statistical features can be additionally derived as following deanonymisation. More clearly, without deanonymistion, there would be no difference or distinguishing between internal-characterised and external-characterised features of flows. Thus, it allows the statistical analysis of the small scale communication of one external host and its internal clients and vice versa in terms of transmitted packets, internal-arrival durations, and port-used patterns.
Definition
| Feature | Description |
|---|---|
| mean_in_pkts | The mean of total packets of the same group of flows (from internal IP to external IP) |
| var_in_pkts | he variance of total packets of the same group of flows
(from internal IP to external IP) |
| p_x_in_pkts | Probability density of Gaussian distribution of packets of internal to external flows |
| mean_out_pkts | The mean of total packets of same group of flows (from
external IP to internal IP) |
| var_out_pkts | The variance of total packets of the same group of flows
(from external IP to internal IP) |
| p_x_out_pkts | Probability density of Gaussian distribution of packets of
external IP to internal IP) |
| mean_inter_arrival | The mean of inter-arrival time of flows which have
direction of internal to external |
| var_inter_arrival | The variance of inter-arrival time of flows which have
direction of internal to external |
| p_x_inter_arrival | Probability density of Gaussian distribution of inter-
arrrival time of flows which have direction from internal to external |
| min_in_port | Minimal port among outgoing flows which have direction
from internal to external |
| max_in_port | Maximal port among outgoing flows which have
direction from internal to external |
| min_out_port | Minimal port among incoming flows which have direction
from external to internal |
| min_out_port | Maximal port among incoming flows which have
direction from external to internal |
| deanonymisation | 0 for outgoing flow, 1 for incoming flow |
| internal_port_hashcode | The hashcode of port used by internal IP in the same
group of flows |
| external_port_hashcode | The hashcode of port used by external IP in the same
group of flows |
| class | Binary class of flows, 0 for benign, 1 for botnet |
The Fflowsize-based features are: mean_in_pkts, var_in_pkts, p_x_in_pkts, mean_out_pkts, var_out_pkts, p_x_in_pkts
The client-access pattern features are: mean_inter_arrival, var_inter_arrival, p_x_inter_arrival
The port-based features are: min_in_port, max_in_port, min_out_port, max_out_port, internal_port_hashcode, external_port_hashcode
The deanonymisation feature is "deanonymisation". This feature is directly inferred from deanonymisation process.
Temporal analysis
Due to the periodic behaviour of most botnets, a temporal analysis of the Netflow data is required to extract useful features. For this project it was decided to use a Fast Fourier Transform (FFT) analysis method. This method will allow us to extract the frequency which a pair of IPs contact each other. To apply this method the data will first need to be processed. This processing will involve collecting all the flows with the same IP pairs and then sampling them. All the flows will be collected based on the same source IP and destination IP fields. The sampling will involve two methods. The first method will be to sample all the collected flows and setting the value at the start time to be ’1’ and ’0’ in between connection start. This method will create a binary sampling which will be similar to square waves. The second method will involve initialising all the times to zero and then adding one to all the time points where a flow is connected. This method was selected due to the overlap of the flows for the known bots, the next connections started before the last connections had ended. The FFT technique will then be applied to the resulting data from both these methods to provide us with all the frequency found in the data. Finally the Power Spectral Density (PSD) will be computed to identify the most significant frequencies. Due to the square wave format of the sampled data, the first two peaks of the PSD will be selected and the frequencies will be added to the original Netflow data to all flows with those IP pairs. The resulting frequency found from both of the sampling methods will then be tested for usefulness by testing them with other selected features using WEKA. To limit the processing time, it was decided to limit the flows to be concerned with. The flows were limited by removing all IP pairs found only once in the data.
Network Traffic Capture
Cisco routers or capable ones are configured to emit Netflow flows to border gateway PC. On this machine there would be a Netflow collector responsible for collecting the flows and interpret the binary data into human readable fields of flows such as source IP, source Port, destination IP, destination Port, traffic volumes, etc. The traffic can be visualised using a specialised tool.
Testing and implementation on Weka
After selecting/extracting a list of useful features, the next stage is import the dataset into Weka, trying to use searched Machine Learning algorithm and selected features to classify botnet.
In this stage, each team member will be allocated to test and implement for one type of selected tree-based ML algorithm. They will test for classify result and implement the algorithm and features accordingly to obtain a higher classify rate.
In the test stage, Jonathan & Jing will test the FFT feature that they derived in section 5.2.2 whereas Yao & Thien will test for rest features.
This stage arises from the need to make the system work in real time but still remain able to detect a sufficiently high percentage of botnets on the network tested.
Test under real-time condition
The final stage is a time dependent objective. The objective entails taking the information gathered during the first three stages and making an optimal system, which will classify the network flows in real time. This objective is due to the requirement that the system produces by this project needs to function on any network with a range of bandwidth and data speed.
Management Plan
Risks Management
Potential or foreseeable risks certainly exist in this project. As such, these risks must be identified and analysed in order to reduce and potentially avoid their negative impact on the project. The risks are sorted into two aspects which are human error and technical error.
Absences from regular group meeting or compulsory event could limit the progress of the project. To deal with this issue, all meetings are minuted and the member who has been absent will be required to catch up in a promptly manner. Moreover, ground rules for the team have been established in the team charter.
Inadequate time management might generate risk in this project. For instance, underestimating the time required for a particular task could lead to delay in completing the dependent tasks. To limit the impact of this risk, the project progress will be monitored weekly with assistance from the supervisors. As such, any delay will be promptly resolved. Data loss can be a serious problem, not in term of human mistake but in more technical ways. Computer malfunction is the most common reason in regard to data loss. Therefore, a copy of all documents will be kept on Google Drive and all data sets will be kept on multiple external hard drive for security.
In addition, the capability of the software to be scalable to function in real time and handle an increasing amount of data is a major consideration in term of risk management. In order to limit this risk, the speed of the system will be closely monitored to provide enough time to implement assisting measures.
However, some unforeseen risks may also exist in this project. To maintain the quality of the project, quality management will be implemented in this project. More specifically, scheduling, reviewing and documenting are considerable elements of the quality management process. This quality management process is defined in more details in section 5.4 of this document.
| Risk | likelihood | Severity | Risk Index |
| Regular team member absences | Occasional | Marginal | 11 |
| Incorrect time management | Occasional | Significant | 7 |
| Data loss | Remote | Significant | 11 |
| System Scalability | Probable | Significant | 4 |
Table 1: Risk assessment table
These risk index were defined using the tables in appendix B.
As can be seen from the table, the two most important risks are the system scalability and the incorrect time management and so will require extra care throughout the project life cycle.
Budget
This project has minimal cost due to being software based. The software required for this project are already available(MatLab) or available freely(Weka). The equipment required to this project involve only the computers already available within the facilities. Additionally since the facilities(rent, power,...) and staff costs for this project have been removed from consideration, there is no facilities or staff cost for this project. Therefore this project is budgeted to be at no costs.
Timelines
The timeline for this project is shown in appendix A, which contains the whole project deliverables, milestones and each project task. The timeline clearly shows every tasks expected start and finish time, as well as the due day of every milestones for this project. Furthermore, it shows the group members allocated to the tasks.
Quality Management
To guarantee to quality of the documents produced during this project, a document reviewing process has been put into place. The document reviewing process involves a team member being assigned the task of
reviewing the work completed by another team member. Another review will be done by the documents manager and the team manager after the document is complete. At the same time, the project supervisors will be provided with the documents to allow their feedback to be used to improve the documents. This will allow all documents to be reviewed at multiple stages.
Citations and References
[1] Spamhaus, [online], http://www.spamhaus.org/news/article/720/spamhaus-botnet-summary-2014
[2] Blue Coat, The Inception Framework: Cloud-Hosted APT
[3] H. Suo, J. Wan, C. Zou, J. Liu, Security in the Internet of Things: A Review
[4] L. Bilge,D. Balzarotti,W. Robertson, E. Kirda, C. Kruegel, DISCLOSURE: Detecting Botnet Command and Control Servers Through Large-Scale NetFlow Analysis
[5] F. Haddadi, J. Morgan, Filho E.G., Zincir-Heywood A.N. , Botnet Behaviour Analysis Using IP Flows: With HTTP Filters Using Classifiers
[6] Weka. [Online]. http://www.cs.waikato.ac.nz/ml/weka/
[7] I. H. Witten, E. Frank, and M. A. Hall, Data Mining: Practical Machine Learning Tools and Techniques, Third Edition, 3 edition. Burlington, MA: Morgan Kaufmann, 2011.
[8] WEKA, ARFF (book version), The University of Waikato. [Online]. Available: https://weka.wikispaces.com/ARFF+%28book+version%29
[9] B. McALEER, V. Cao, T. Moschou, G. Cullity, Development of Machine Learning Techniques for Analysing Network Communications, School of electrical and electronic engineering, The Universty of Adelaide, 2014
[10] I. Witten and E. Frank, Data Mining: Practical Machine Learning Tools and Techniques with java Implementations, 2nd ed. Morgan Kaufmann Publishers, 2005.
[11] https://www.coursera.org/learn/machine-learning/outline?module=2B0GR
[12] M. Hall, E. Frank, G. Holmes, B. Pfahringer, P. Reutemann, and I. H. Witten, The weka data mining software: An update, SIGKDD Explor. Newsl., vol. 11, no. 1, nov 2009.
[13] http://www.cs.waikato.ac.nz/ml/weka/mooc/dataminingwithweka/
[14] F. Tegeler, G. Vigna, X. Fu, C. Kruegel, BotFinder: Finding Bots in Network Traffic Without Deep Packet Inspection
[15] J. Raoux, Y. Lu, T. Pham, J. Wang, Project Proposal Draft, 2015
Appendix
Appendix A: Gantt Chart for this project
Due to limitation caused by the wiki, the Gantt chart cannot be imported. This issue will be resolved as soon as possible.
Appendix B: Risk Index Table
| Description | Level | Specific event |
| Frequent | A | Likely to occur frequently |
| Probable | B | Will occur several times during the project life cycle |
| Occasional | C | Likely to occur sometime in the project life cycle |
| Remote | D | Unlikely to occur in the project life cycle |
| Improbable | E | Can be assumed never to occur |
| Probability of Occurrence | Severity I Catastrophic | Severity II Significant | Severity III Marginal | Severity IV Negligible |
| Frequent | 1 | 3 | 6 | 10 |
| Probable | 2 | 4 | 8 | 14 |
| Occasional | 3 | 7 | 11 | 17 |
| Remote | 7 | 11 | 16 | 19 |
| Improbable | 10 | 16 | 18 | 20 |
Appendix C: Overview of the Complete System
Appendix D: Data file format interpretable by WEKA
Simple Netflow record extracted from Netflow data have the fields similar but not limited to:
| Time | srcIP | srcPort | dstIP | dstPort | Protocol | class |
| 2015-04-15 12:12:12 | 192.168.2.1 | 12345 | 72.67.123.12 | 80 | TCP | Botnet |
| 2015-04-15 13:13:13 | 192.168.5.120 | 34567 | 80.45.67.123 | 21 | udp | Benign |
According to Witten et al. [7], the native format supported by WEKA is ARFF format. Several converters available in WEKA which can convert other format into ARFF format:
- Spreadsheet files with extension .csv
- C4.5s native file format with extensions .names and .data
- Serialised instances with extension .bsi
- LIBSVM format files with extension .libsvm
- SVM-Light format files with extension .dat
- XML-based ARFF format files with extension .xrff
Depending on the file extension, the appropriate converter would be used to convert the data file to ARFF. For the above Netflow records, the corresponding ARFF format is similar to [8]:
% 1. Tile: Netflow records dataset
% 2. Project: Detecting Botnet
% Information on Project: students, supervisor
% Date
@relation network
@attribute time date yyyy-MM-dd HH:mm:ss
@attribute srcIP string
@attribute srcPort numeric
@attribute dstIP string
@attribute dstPort numeric
@attribute Protocol TCP,UDP,ICMP
@attribute class botnet, benign
@data
2015-04-15 12:12:12, 192.168.2.1, 12345, 72.67.123.12, 80, TCP, Botnet
2015-04-15 13:13:13, 192.168.5.12, 34567, 80.45.67.123, 21, UDP, Benign
Appendix E: CSV
The Netflow records need to be converted into CSV format (comma separated values) such as:
srcIP, srcPort, dstIP, dstPort, Protocol, class
192.168.2.1, 12345, 72.67.123.12, 80, TCP, Botnet
192.168.5.120, 34567, 80.45.67.123, 21, UDP, Benign
The IPs are treated as string, port numbers are numeric values ranging from 0 to 65335, the protocol is a string value in the set of TCP, UDP or ICMP and the predictive feature is class. As shown by Witten et al. [7], WEKA can load .csv file to convert it to ARFF format as described above. To obtain CSV-formatted dataset, a tool can be used to convert Netflow records into .csv format.